接近超人水平!最強大的公開圍棋AI系統「KataGo」勝率達50%
機器之心報道
機器之心編輯部
AI:「我能戰勝頂級人類玩家。」另一個 AI:「我玩不過人類,但我能戰勝你。」
近幾年,自我博弈中的強化學習已經在圍棋、國際象棋等一系列游戲中取得了超人的表現。此外,自我博弈的理想化版本還收斂于納什均衡。納什均衡在博弈論中非常著名,該理論是由博弈論創始人,諾貝爾獎獲得者約翰 · 納什提出,即在一個博弈過程中,無論對方的策略選擇如何,當事人一方都會選擇某個確定的策略,則該策略被稱作支配性策略。如果任意一位參與者在其他所有參與者的策略確定的情況下,其選擇的策略是最優的,那么這個組合就被定義為納什均衡。
之前就有研究表明,自我博弈中看似有效的連續控制策略也可以被對抗策略利用,這表明自我博弈可能并不像之前認為的那樣強大。這就引出一個問題:對抗策略是攻克自我博弈的方法,還是自我博弈策略本身就能力不足?
為了回答這個問題,來自 MIT、 UC 伯克利等機構的研究者進行了一番研究,他們選擇自我博弈比較擅長的領域進行,即圍棋(Go)。具體而言,他們對公開可用的最強圍棋 AI 系統 KataGo 進行攻擊。針對一個固定的網絡(凍結 KataGo),他們訓練了一個端到端的對抗策略,僅用了訓練 KataGo 時 0.3% 的計算,他們就獲得了一個對抗性策略,并用該策略攻擊 KataGo,在沒有搜索的情況下,他們的策略對 KataGo 的攻擊達到了 99% 的勝率,這與歐洲前 100 名圍棋選手實力相當。而當 KataGo 使用足夠的搜索接近超人的水平時,他們的勝率達到了 50%。至關重要的是,攻擊者(本文指該研究學到的策略)并不能通過學習通用的圍棋策略來取勝。
這里我們有必要說一下 KataGo,正如本文所說的,他們在撰寫本文時,KataGo 還是最強大的公開圍棋 AI 系統。在搜索的加持下,可以說 KataGo 非常強大,戰勝了本身就是超人類的 ELF OpenGo 和 Leela Zero。現在該研究的攻擊者戰勝 KataGo,可以說是非常厲害了。
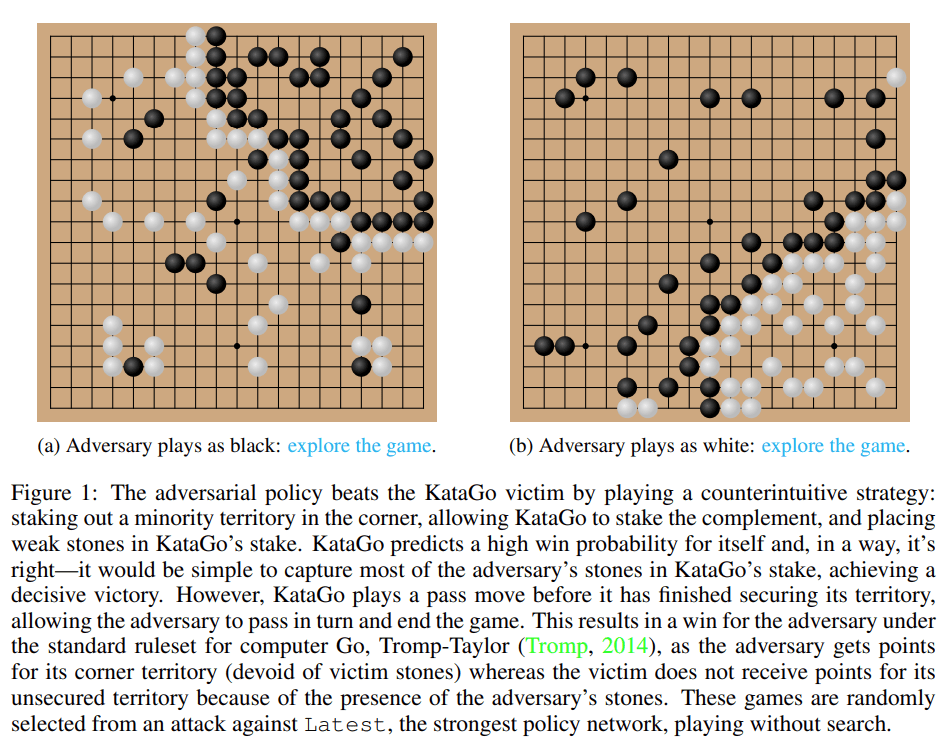
圖 1:對抗策略打敗了 KataGo 受害者。

論文地址:https://arxiv.org/pdf/2211.00241.pdf
研究主頁:https://goattack.alignmentfund.org/adversarial-policy-katago?row=0#no_search-board
有趣的是,該研究提出的對抗策略無法戰勝人類玩家,即使是業余選手也能大幅勝過所提模型。
攻擊方法
KataGo、AlphaZero 等之前的方法通常是訓練智能體自己玩游戲,游戲對手是智能體自己。而在 MIT、UC 伯克利等機構的這項研究中,攻擊者(adversary)和固定受害者(victim)智能體之間進行博弈,利用這種方式訓練攻擊者。該研究希望訓練攻擊者利用與受害者智能體的博弈交互,而不只是模仿博弈對手。這個過程被稱為「victim-play」。
在常規的自我博弈中,智能體通過從自己的策略網絡中采樣來建模對手的動作,這種方法的確適用于自我博弈。但在 victim-play 中,從攻擊者的策略網絡中建模受害者的方法就是錯誤的。為了解決這個問題,該研究提出了兩類對抗型 MCTS(A-MCTS),包括:
A-MCTS-S:在 A-MCTS-S 中,研究者將攻擊者的搜索過程設置如下:當受害者移動棋子時,從受害者策略網絡中采樣;當輪到攻擊者移動棋子時,從攻擊者策略網絡中采樣。
A-MCTS-R:由于 A-MCTS-S 低估了受害者的能力,該研究又提出了 A-MCTS-R,在 A-MCTS-R 樹中的每個受害者節點上為受害者運行 MCTS。然而,這種變化增加了攻擊者訓練和推理的計算復雜性。
在訓練過程中,該研究針對與 frozen KataGo 受害者的博弈來訓練對抗策略。在沒有搜索的情況下,攻擊者與 KataGo 受害者的博弈可以實現 >99% 的勝率,這與歐洲前 100 名圍棋選手的實力相當。此外,經過訓練的攻擊者在與受害者智能體博弈的 64 個回合中實現了超過 80% 的勝率,研究者估計其實力與最優秀的人類圍棋棋手相當。
值得注意的是,這些游戲表明,該研究提出的對抗策略并不是完全在做博弈,而是通過欺騙 KataGo 在對攻擊者有利的位置落子,以過早地結束游戲。事實上,盡管攻擊者能夠利用與最佳人類圍棋選手相當的博弈策略,但它卻很容易被人類業余愛好者擊敗。
為了測試攻擊者與人類對弈的水平,該研究讓論文一作 Tony Tong Wang 與攻擊者模型實際對弈了一番。Wang 在該研究項目之前從未學習過圍棋,但他還是以巨大的優勢贏了攻擊者模型。這表明該研究提出的對抗性策略雖然可以擊敗能戰勝人類頂級玩家的 AI 模型,但它卻無法擊敗人類玩家。這或許可以說明一些 AI 圍棋模型是存在 bug 的。
評估結果
攻擊受害者策略網絡
首先,研究者對自身攻擊方法對 KataGo (Wu, 2019) 的表現進行了評估,結果發現 A-MCTS-S 算法針對無搜索的 Latest(KataGo 的最新網絡)實現了 99% 以上的勝率。
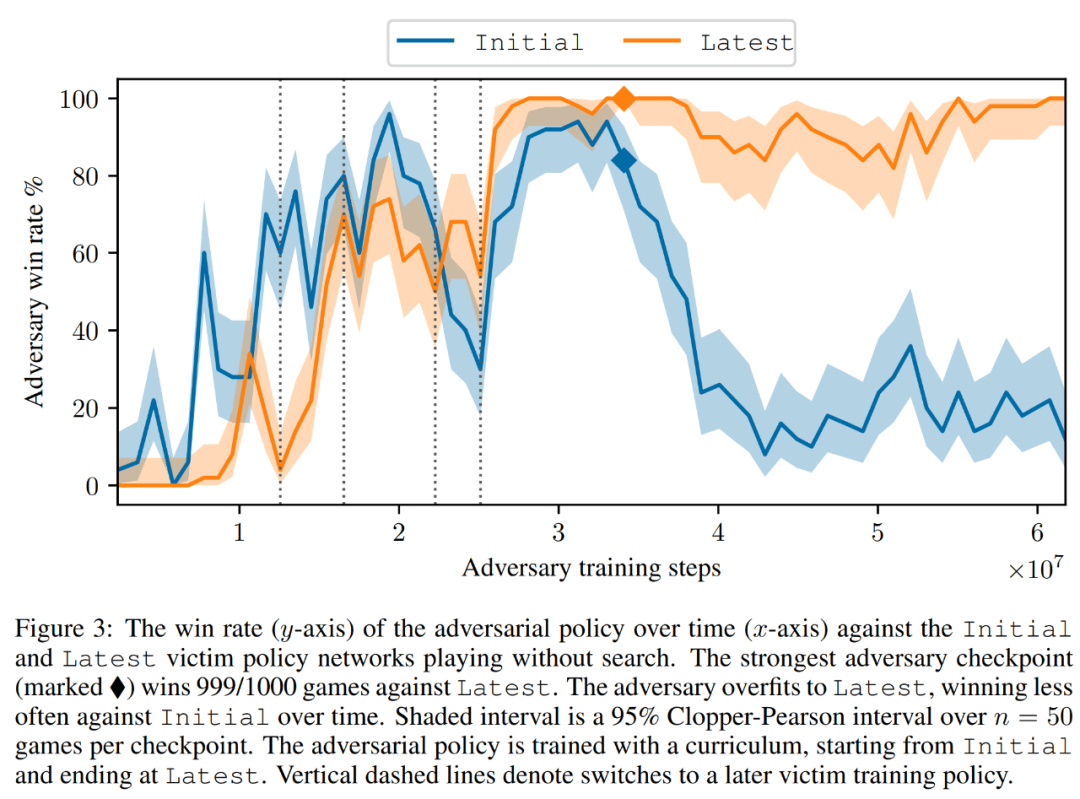
如下圖 3 所示,研究者評估了自身對抗策略對 Initial 和 Latest 策略網絡的表現。他們發現在大部分訓練過程中,自身攻擊者對兩個受害者均取得很高的勝率(高于 90%)。但是隨著時間推移,攻擊者對 Latest 過擬合,對 Initial 的勝率也下降到 20% 左右。
研究者還評估了對 Latest 的最佳對抗策略檢查點,取得了超過 99% 的勝率。并且,如此高的勝率是在對抗策略僅訓練 3.4 × 10^7 個時間步長的情況下實現的,這一數據是受害者時間步長的 0.3%。
遷移到有搜索的受害者
研究者將對抗策略成功地遷移到了低搜索機制上,并評估了上一節訓練的對抗策略對有搜索 Latest 的能力。如下圖 4a 所示,他們發現在 32 個受害者回合時,A-MCTS-S 對受害者的勝率下降到了 80%。但這里,受害者在訓練與推理時都沒有搜索。
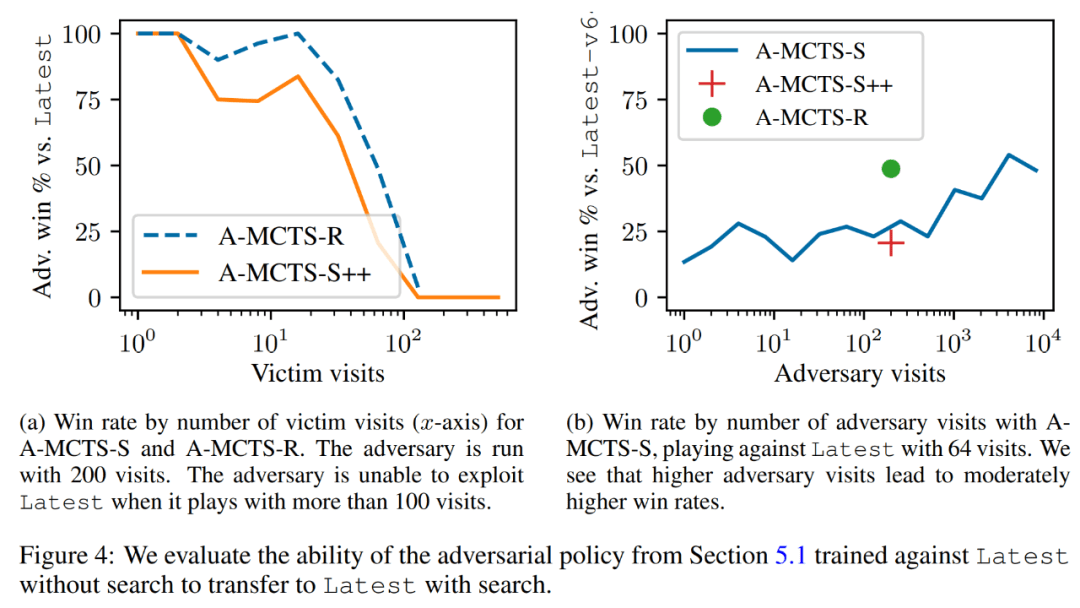
此外,研究者還測試了 A-MCTS-R,并發現它的表現更好,在 32 個受害者回合時對 Latest 取得了超過 99% 的勝率,但在 128 個回合時勝率下降到 10% 以下。
在圖 4b 中,研究者展示了當攻擊者來到 4096 個回合時,A-MCTS-S 對 Latest 最高取得了 54% 的勝率。這與 A-MCTS-R 在 200 個回合時的表現非常相似,后者取得了 49% 的勝率。
其他評估
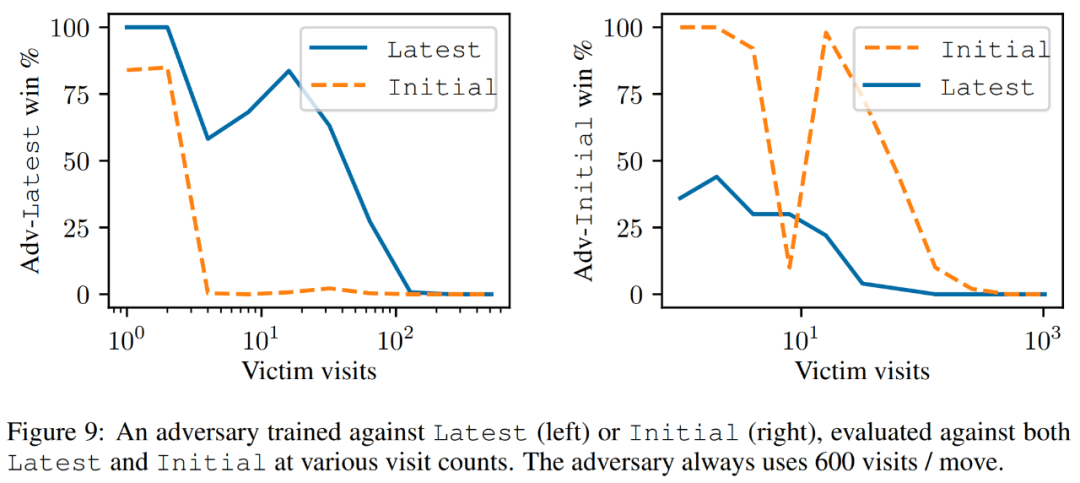
如下圖 9 所示,研究者發現,盡管 Latest 是一個更強大的智能體,但針對 Latest 訓練的攻擊者在對抗 Latest 時要比 Initial 表現更好。
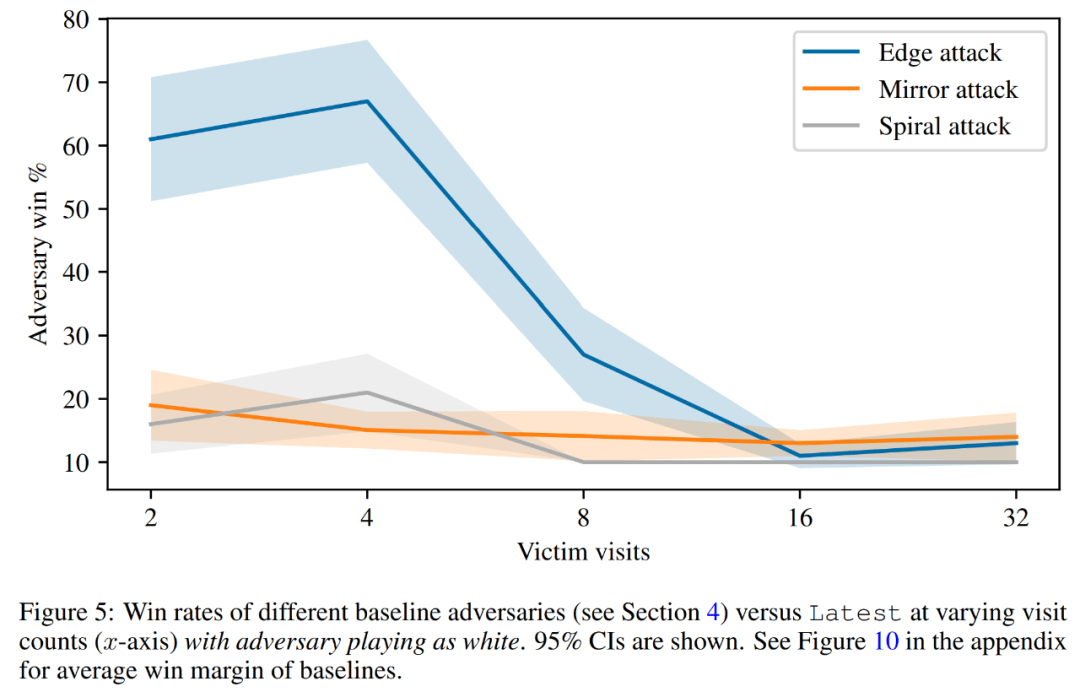
最后,研究者探討了攻擊原理,包括受害者的 value 預測和硬編碼防御評估。如下圖 5 所示,所有的基線攻擊都要比他們訓練的對抗策略表現差得多。
更多技術細節請參閱原論文。
來源:IT時代網
IT時代網(關注微信公眾號ITtime2000,定時推送,互動有福利驚喜)所有原創文章版權所有,未經授權,轉載必究。
創客100創投基金成立于2015年,直通硅谷,專注于TMT領域早期項目投資。LP均來自政府、互聯網IT、傳媒知名企業和個人。創客100創投基金對IT、通信、互聯網、IP等有著自己獨特眼光和豐富的資源。決策快、投資快是創客100基金最顯著的特點。




熱門文章
精彩評論
 小何華為現在牛的不只是設備商了,,華為的手機現在也是全球銷量不錯,國內也算是老大了,之前用小米,,現在都改華為了。。產品確實不錯。
小何華為現在牛的不只是設備商了,,華為的手機現在也是全球銷量不錯,國內也算是老大了,之前用小米,,現在都改華為了。。產品確實不錯。- 小何三星手機在中國還有市場嗎?看看現在滿大街的vivo和oppo ,,華為,,小米線下店,,就是知道三星的市場基本沒有了。。
- 小何滴滴打車現在也沒有之前那么火了,,補貼也少了。。
- 小何今日頭條要把騰訊的地方各頻道給霸占了。。