揭秘首批中文電腦字體誕生過程,將漢字「搬」進數碼設備有多難?
新的電子設備開機時,屏幕映出的首個交互頁面,往往是系統語言選擇。
你可以上下滑動,選擇中文、英文、日文等多達上百種的文字。但如果將時間撥回 40 多年前,這一選項可能只有寥寥幾種,而且沒有中文。
我國文字的歷史源遠流長,但其數字化的歷程卻并不久遠。我們現在之所以能在電子設備上閱讀中文,離不開最初花費巨大力氣,將中文‘搬’至電腦上的那一群人。
最近,斯坦福大學獲得了 2500 余件現代中國信息技術收藏品,包括幾十臺珍稀的中文打字機、文字處理器和電腦等物品,堪稱世界上最大的中國現代 IT 歷史合集。

▲首批中文數字字體模型。 圖片來自:斯坦福大學
該校一位研究中國歷史的教授托馬斯·穆拉尼(Thomas Mullaney),在這些珍貴的藏品里發現了許多有趣的故事。其中就包括全球首批中文數字字體,是如何被制作出來的。
托馬斯將這段艱辛但充滿藝術的歷程,在《麻省理工科技評論》上講述了出來。我們也得以機會看見這個具有時代意義的歷史片段。
▲托馬斯·穆拉尼
一臺機器帶來的契機
故事要從一個訂單開始說起。
20 世紀 80 年代初,美國圖形藝術研究基金會 (Graphics Arts Research Foundation) 找到了路易斯·羅森布魯姆(Louis Rosenblum),想請他的團隊,為其正在開發的機器 Sinotype III 創建出中文字體。
當時路易斯已年近 6 旬,畢業于麻省理工學院的他,是一名資深的印刷、排版專家。路易斯在 1965 年創立了 Photography Systems 公司,專門解決數字工程、攝影、應用數學等相關問題。

▲路易斯·羅森布魯姆
雖然路易斯及其團隊此前和圖形藝術研究基金會有過多次合作,但這次為 Sinotype III 創建中文字體的項目,卻是最棘手的。
因為當時中國還沒開始生產個人電腦,其他國家或地區生產的電腦無法處理中文。所以在給 Sinotype III 這臺實驗性機器開發中文字體前,路易斯的團隊需要先對蘋果二代電腦(Apple II)編程,使其能夠以中文運行。

▲Apple II。 圖片來自:Wiki
萬事開頭難。由于蘋果二代的 DOS 3.3 操作系統,無法輸入和輸出漢字文本,所以必須得從頭編程,包括編寫一個中文文字處理器。為此,其團隊花費了幾個月的功夫。
他們想出的解決方案,是先通過 BASIC 編程語言,編寫一個‘Gridmater’程序,然后將該程序放入蘋果二代電腦的軟盤上運行。如此一來,便能創建并保存漢字的數字位圖了。
接著,將設計好的漢字位圖及其相應的代碼,植入到系統數據庫,便可讓 Sinotype III 機器處理并顯示中文了。

▲Sinotype III 顯示器的照片,顯示了 Gridmaster 程序和漢字‘電’。 圖片來自:斯坦福大學
這里插入一個背景知識。早期的數字字體,均采用位圖圖像(也稱點陣圖像)來顯示。
這是一種常見的儲存圖像的方式,我們今天相機拍攝的照片、截圖,儲存方式均屬于位圖。一張 JPEG、BMP、GIF 等格式的圖片,是由很多像素點組成,這些點經過排列和染色,便構成了圖樣。
比如我們可以在電腦上將一張圖片放大,放大至一定程度,便可看到正方形的像素點了。早期的字體便是在一定大小的網格內,通過排列和染色形成的。
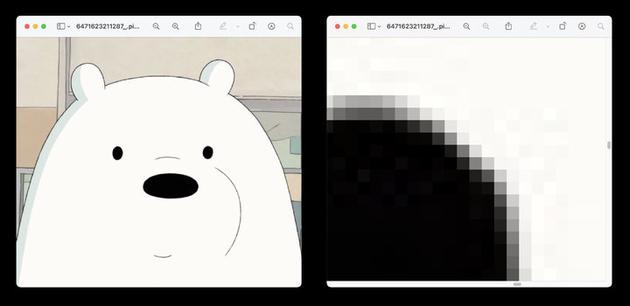
▲ 將左圖的眼睛部位放大,便可看到像素點了
中文數字字體,可比英文難做多了
中文數字字體之所以難做,首要原因就是漢字的數量實在太多了,其次是因為漢字的字形十分復雜多樣。
在計算機問世之初,工程師和設計師約定采用大小為 5X7 的位圖網格,來創建低分辨率的英文數字字體。如此一來,每個字符的大小約 5 個字節,計算機的內存不會有太多負擔。
在美國信息交換標準代碼(ASCII)中儲存的所有 128 個低分辨率字符,包括英文字母表中的每個字母、數字 0 到 9,以及常見的標點符號,共計需要 640 字節的內存。而當時蘋果二代的內存為 64KB,可以輕松承載英文字體庫。
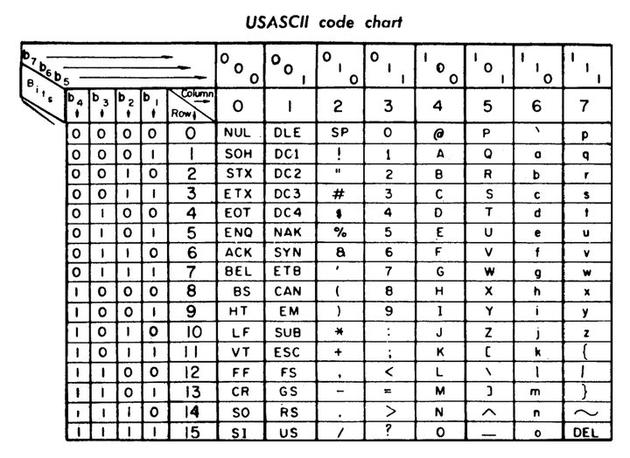
▲ASCII 字符表
而中文由于字形復雜,在 5X7 大小的網格中會糊作一團,難以辨認。因此至少需要一個 16X16 或者更大的網格。
這樣換算下來,每個中文字符的大小至少有 32 字節。如果將 70000 個低分辨率的漢字打包,內存至少需要 2MB。再退一步,即便字庫內只放進 8000 個常用的漢字,也需要約 256KB 的內存。
這無疑是一個大難題。因為在上世紀 80 年代初,大多數 PC 的總內存容量不超過 64KB,根本裝不下龐大的中文位圖字庫。
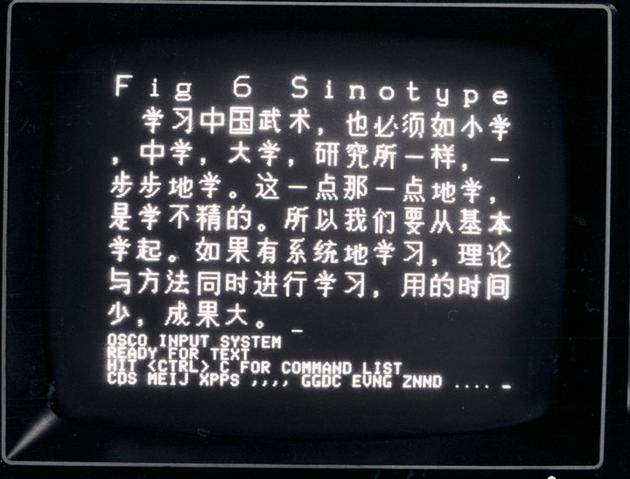
▲Sinotype III 顯示器的照片,顯示了中文字體。 圖片來自:斯坦福大學
內存告急并不是最令人頭疼的,因為這可以隨著 PC 軟硬件的進步得以解決。如何在 16X16 的低分辨率網格中,創造出既容易辨認又美觀的中文字體,是更棘手的難題。
為此,路易斯團隊的設計師們花了數年時間,嘗試創造出滿足低內存要求,且清晰易認,甚至有書法美感的中文位圖。其中,凌煥銘(Huan-Ming Ling)和艾倫迪喬瓦尼(Ellen Di Giovanni)的貢獻最為突出。
他們先是借助紙、筆、修正液來手繪出漢字的位圖,然后借助上文提到的 Gridmater 程序將其數字化,植入到 Sinotype III 的系統中。

▲Sinotype III 顯示的中文字體。 圖片來自:Courtesy of Bruce Rosenblum
制作背后的匠人精神
托馬斯教授在檔案資料里,發現了路易斯團隊設計漢字位圖的全過程。在一個裝滿格子圖的冊子中,記錄了設計師們是如何通過手繪散點符號來創造漢字位圖的。
我們都知道,漢字的筆畫并非‘橫平豎直’的,入口筆畫、出口筆畫、筆畫漸變都有著豐富的細節。這也是設計師們面臨的核心問題,即如何在 16X16 的方格中,盡可能將這種書法美展現出來。
在這本格子冊中,可以發現每個漢字都經過設計師精心繪制。綠色的‘X’是最初的標記,交由漢字編輯審核后,如果哪里不夠規范,路易斯及其團隊便會用修正液蓋住原本的標記,再用紅色的‘X’標記上去。
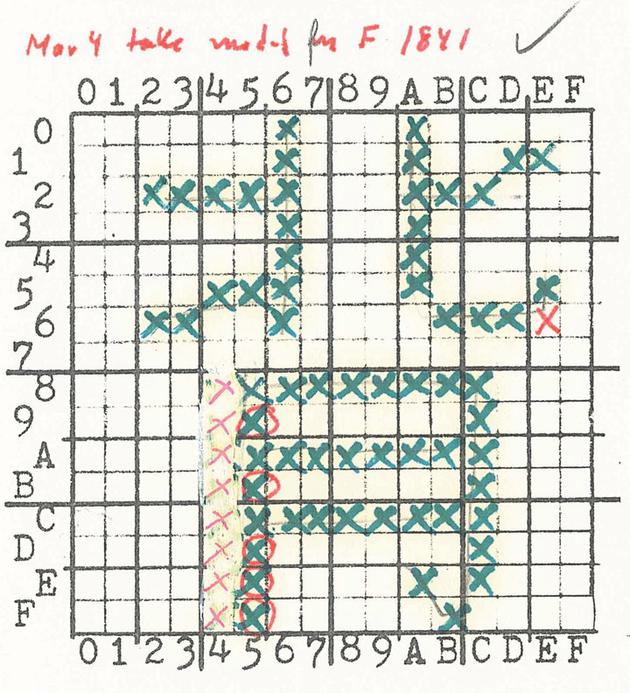
▲‘背’字的位圖草稿。 圖片來自:斯坦福大學
經歷反復修改,經過最終確認的位圖,才會輸入至系統中。
如果要滿足消費者的需求,字庫里至少要包含 3000 個常用的漢字。這個工程量對于團隊來說是很大的。人們可能會猜測,他們是否會尋找一些討巧的方法。
例如,對于相同偏旁部首的漢字,可以直接將偏旁部首復制過去。就像下圖中‘評’、‘讀’都是言字旁,按理說設計師只需要設計右側不一樣的部分就可以。
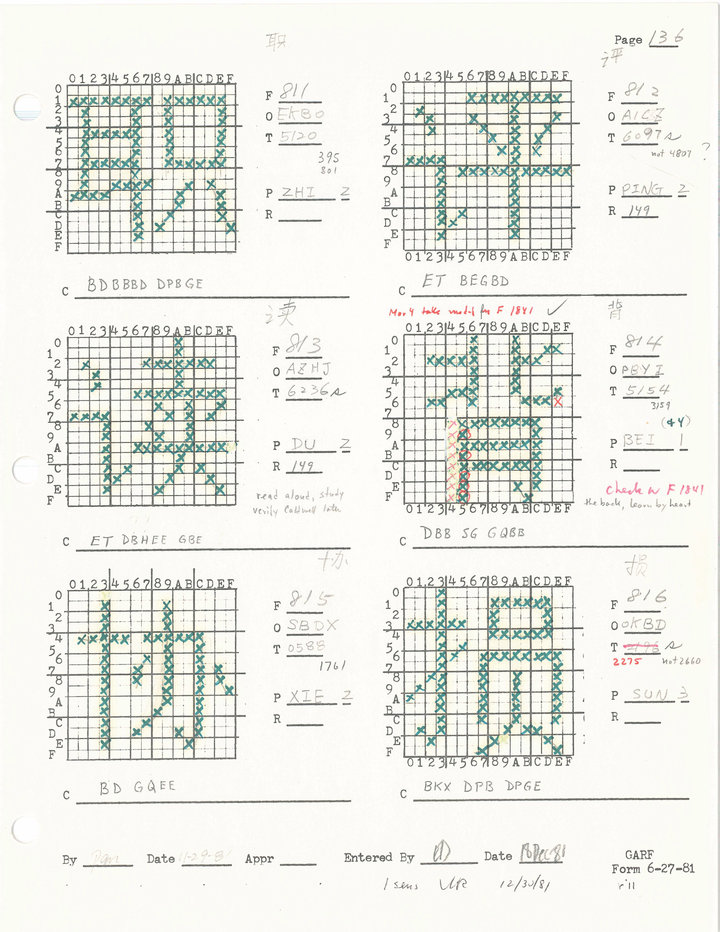
▲中文位圖草稿。 圖片來自:斯坦福大學
但是托馬斯教授發現檔案里類似的工作機制很少。路易斯堅持要求設計師逐字調整、設計,以確保每個字的偏旁部首看起來是協調的。即便有些改動十分細微,令人難以察覺。
托馬斯教授按照檔案資料重新復現了 Sinotype III 的中文字體。可以發現同樣為‘女’字旁的‘娟’和‘娩’,兩個字的‘女’字旁的設計樣式并不一樣。
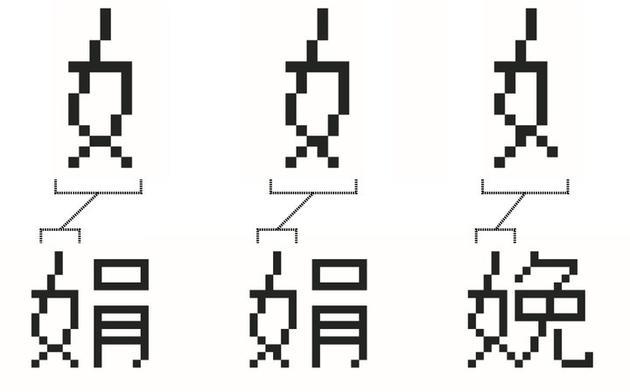
▲可以看出‘女’字旁的不同嗎? 圖片來自:斯坦福大學
‘女’字旁在‘娟’字中的寬度為 6 個像素(網格),而在‘娩’字中只有 5 個像素。另外‘娩’字的‘女’字旁撇點和撇的筆畫,要比‘娟’多一個像素,視覺上更加修長。
這樣一絲不茍的設計并非個例。托馬斯教授在字體庫里發現了大量類似的工作,當他將位圖的草稿與最終成品放在一起對比時,還能看到許多細微、有趣的變化。
比如在‘羅’字中,左下角的筆畫最初是以 45°向下伸展的。但最終版本,筆畫的盡頭被‘拉平’,更符合書法的藝術感。
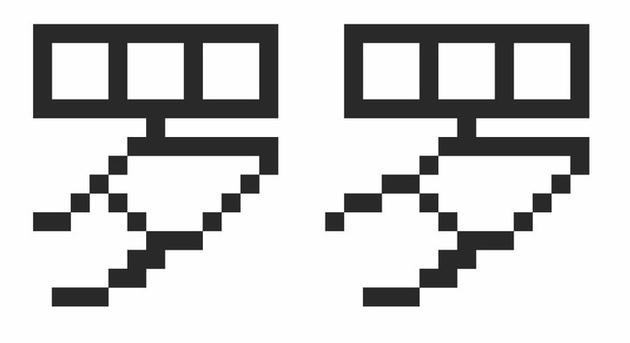
▲‘羅’字的兩個版本,左為最終版。 圖片來自:斯坦福大學
可以看出,添加或縮減一個像素,便會對整體的平衡感、美感造成影響。這也體現出設計師們在創作首批字體的艱辛,以及背后的匠人精神。
實際上,16X16 的網格,對于創作中文字體并不是很友好。最主要的問題是對稱性。
我們知道,大量的漢字是具有對稱性的,而根據數學的規則,只有奇數大小的空間區域,才能創建出完全對稱的形體。
因此,路易斯及其團隊決定只利用 16X16 網格中的 15X15 區域,來實現漢字的對稱。這進一步縮小了設計師的空間,對設計工作提出了更高的要求。

▲ 山、中、田的對稱與非對稱。 圖片來自:斯坦福大學
得益于團隊孜孜不倦的努力和一絲不茍的態度,Sinotype III 的中文字體庫項目順利完成。盡管它并未商業發布,但它的確是世界上最早能處理、顯示、輸入輸出中文的 PC 之一。
當然,路易斯及其團隊制作字體的方法,在當今的技術語境下看起來似乎太過古板和幼稚。現在廣泛使用的 TrueType 字體技術,能夠以矢量方式存儲字體,占用空間小、渲染快、顯示效果清晰銳利。

▲如今多數字體均是 TrueType 格式。 圖片來自:themex
但正是他們使用‘笨方法’,逐字畫稿、反復修改,才讓漢字得以進入數字世界。而‘當代畢昇’王選院士主持研制的高分辨率字形信息壓縮技術,更是徹底地解決了漢字編碼儲存的困境。
在這些前輩們的努力下,中文才沒有被互聯網大潮落下,漢語拉丁化的理論被掃進歷史垃圾堆。我們今天能夠使用中文在互聯網上沖浪,應感謝他們曾為此付出的青春。【責任編輯/周末】
來源:愛范兒
IT時代網(關注微信公眾號ITtime2000,定時推送,互動有福利驚喜)所有原創文章版權所有,未經授權,轉載必究。
創客100創投基金成立于2015年,直通硅谷,專注于TMT領域早期項目投資。LP均來自政府、互聯網IT、傳媒知名企業和個人。創客100創投基金對IT、通信、互聯網、IP等有著自己獨特眼光和豐富的資源。決策快、投資快是創客100基金最顯著的特點。




熱門文章
精彩評論
 小何華為現在牛的不只是設備商了,,華為的手機現在也是全球銷量不錯,國內也算是老大了,之前用小米,,現在都改華為了。。產品確實不錯。
小何華為現在牛的不只是設備商了,,華為的手機現在也是全球銷量不錯,國內也算是老大了,之前用小米,,現在都改華為了。。產品確實不錯。- 小何三星手機在中國還有市場嗎?看看現在滿大街的vivo和oppo ,,華為,,小米線下店,,就是知道三星的市場基本沒有了。。
- 小何滴滴打車現在也沒有之前那么火了,,補貼也少了。。
- 小何今日頭條要把騰訊的地方各頻道給霸占了。。